title: “MySQL基础02-MySQL索引原理” subtitle: “” layout: post author: “Geooo” header-img: “” header-style: text tags: - MySQL
MySQL索引的数据结构
在InnoDB中,表都是根据主键顺序以索引的形式存放的,InnoDB使用了 B+ 树索引模型,所以数据都是存储在B+树中的。 下面对比一下排序数组二分法,平衡二叉树,Hash,B树,B+树的特点
排序数组二分法
二分法是我们常用的一种查找算法,可以有效的提升数据找找的效率,其实现思路是:
-
1、首先对数据集进行排序。
-
2、找到数据集中间位置的节点。
-
3、用查找的条件和间节点进行比较,等于则直接返回,中间节点数据小于查找条件则说明数据在排序列表的左边,大于则说明数据在排序列表的右边。

二叉树查找树
二叉查找树充分了利用二分法的思维提升了数据查找的效率,不过我们在构建二叉树的时候就会发现很容易出现一个问题, 就是二叉查找树的“高度”不稳定,同样的数据插入的先后顺序不一样,就很有可能变成下图一样的结构。
如果树的节点变成线性结构,那么就会极大的降低我们的查询效率,所以我们必须要有一种方式来保证二叉树节点的平衡,让树的节点高度差不会太大,这个时候就衍生了一些平衡算法,最终我们的二叉树就有像AVL树和红黑树这些新产品,我们也称这些新产品为平衡二叉树

平衡二叉树(红黑树)
概念: 平衡二叉树是基于二分法的策略,自适应旋转节点达到高度差平衡,提高数据查找速度的二叉树数据结构。
特点:
- 1) 非叶子节点只能允许最多两个子节点的存在。
- 2) 每个非叶子节点数据分布为:左边的子节点小于当前节点的值,右边的子节点大于当前节点的值。
- 3) 平衡二叉树能保证数据的左右两边的节点层级相差不会大于1。
- 4) 平衡二叉树中没有值相等的重复节点
因为平衡二叉树查询性能和树的层级(h高度)成反比,h值越小查询越快、为了保证树的结构左右两端数据大致平衡降低二叉树的查询难度一般会采用一种算法机制实现节点数据结构的平衡

B树 & B+树(B+Tree)
概念: B Tree 指的是 Balance Tree,也就是平衡树。平衡树是一颗查找树,并且所有叶子节点位于同一层。 B+ Tree 是基于 B Tree 和叶子节点顺序访问指针进行实现,它具有 B Tree 的平衡性,并且通过顺序访问指针来提高区间查询的性能,B+树非叶子节点不存储数据,只有叶子节点才存储数据。
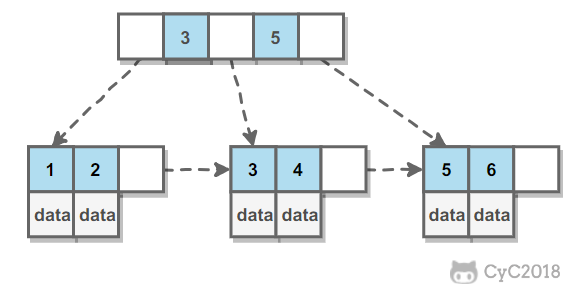
B+树 规则:
- 1) 排序方式:所有节点关键字是按递增次序排列,并遵循左小右大原则
- 2) B+树只有叶子节点存放数据,非叶子节点存放索引的值和指针(指针大小6 bit)
- 3) 叶子节点之间通过指针连接
操作: 进行查找操作时,首先在根节点进行二分查找,然后递归地在指针所指向的节点进行查找。直到找到叶子节点,然后在叶子节点中进行二分法查找。找到key所对应的data。
B+树与红黑树比较
- 1) B+树有更低的树高 红黑树的出度为2,一般 B+Tree的出度都非常大,所以红黑树的树高h明显比B+树高很多。(一般B+树4层树高可以达到千万级别,MySQL默认每一页16k)
- 2) 磁盘读取次数更少 操作系统一般将内存和磁盘分割成固定大小的块,每一块称为一页,内存与磁盘以页为单位交换数据,数据库将索引一个节点的大小置为页的大小,使得一次磁盘IO就可以载入整个节点。 因为B+树的树高比红黑树的树高低,所以B+树IO读取次数会大大减少。在MySQL中一般一次查询查一个索引只要3-4次IO。
- 3) 磁盘预读特性 为了减少磁盘 I/O 操作,磁盘往往不是严格按需读取,而是每次都会预读。预读过程中,磁盘进行顺序读取,顺序读取不需要进行磁盘寻道,并且只需要很短的磁盘旋转时间,速度会非常快。 并且可以利用预读特性,相邻的节点也能够被预先载入。